
「最近話題の“4o Image Generation”ってどこがすごいの?」「ChatGPTで画像が作れるって聞いたけど、どうやって使えばいいの?」
そんな疑問やモヤモヤを感じているあなたへ、本記事がしっかりお応えします。
特に今回は、ChatGPT-4oの画像生成機能(4o Image Generation)について、「進化した技術」「使い方」「活用例」を解説。
初心者でもわかりやすく理解できるようにまとめました。
- GPT-4oの画像生成が他とどう違うのか?進化のポイントがわかる
- 画像を作るための具体的なステップと、効果的なプロンプトの書き方が身につく
- ビジネス・SNSなどの実践的な活用例から、自分の使い道をイメージできる
画像生成AIの進化は、いま大きな転換点を迎えています。
GPT-4oの登場によって、これまでの常識を覆すような高精度かつ柔軟な画像生成が可能になりました。
この記事を読み終えた頃には、「ただの面白機能」ではなく、あなたの創作・発信・ビジネスを支える強力なツールとしてGPT-4oの画像生成を捉えられるようになりますよ。
ぜひ、最後までじっくり読んでみてください。
ChatGPT-4oの画像生成とは?
GPT-4oと4o Image Generationの違い
「GPT-4o」と「4o Image Generation」という言葉を聞いて、「どう違うの?」と疑問に思う方もいるかもしれません。
これらは密接に関連していますが、役割が異なります。
簡単に言えば、GPT-4oはAIモデルそのものであり、4o Image Generationはそのモデルに組み込まれた画像生成機能です。
GPT-4oは、OpenAIが提供する最新のマルチモーダルAIモデルで、テキスト、音声、画像を統合的に扱える高性能なシステムです。
一方で、4o Image Generationは、このGPT-4oが持つ画像生成機能であり、テキストから画像を作成したり、画像を解釈したりする能力を担っています。
以下のように整理できます。
| 用語 | 役割 | 補足説明 |
|---|---|---|
| GPT-4o | モデル本体(AI全体) | テキスト、画像、音声すべて対応 |
| 4o Image Generation | モデル内の画像生成機能 | 主に画像生成と画像理解を担当 |
このように、GPT-4oは包括的なAIであり、その中に「4o Image Generation」という特定のスキルが組み込まれていると考えると分かりやすいでしょう。
画像生成機能の概要と特徴
4o Image GenerationはChatGPT内で動作する画像生成機能であり、従来の画像生成AIと比較して精度や柔軟性が大幅に向上しています。
この機能により、「このシーンでこんな雰囲気のキャラクターが欲しい」といった自然な指示から、高品質な画像を生成できます。
主な特徴は以下の通りです。
- 高解像度な画像出力(標準でも1024×1024px以上)
- 正確な文字描写(例:「AI」などの文字がつぶれない)
- 会話形式で段階的に調整可能(マルチターン対応)
- 人物やキャラクターの一貫性保持
- アップロードした画像を参照して新たな画像を生成可能
特に注目すべきは、画像の中に文字が自然に描かれる点と、キャラクターの一貫性が保たれる点です。
これまでの画像生成AIでは難しかった「プレゼン資料に使えるタイトル画像」や「同一キャラが登場する漫画風の画像」などが、4o Image Generationでは驚くほど簡単に作れます。
たとえば以下のような用途で威力を発揮します。
- SNS用アイキャッチ画像
- ブログやYouTubeのサムネイル
- 漫画やストーリー用連続イラスト
- 広告バナーや商品イメージ
特に「人の顔」や「文字」がしっかり描けるようになったことで、実用性が一気に高まったのが大きな進化です。
利用環境と対応プラン
「GPT-4oを使ってみたい!」と思ったら、まず利用環境やプランを確認しましょう。
現在、この機能はChatGPT Plusプラン(月額20ドル)のユーザー向けに提供されています。
以下に、現在利用可能な環境とプランをまとめます。
| 利用方法 | 必要なプラン | 備考 |
|---|---|---|
| ChatGPT Web版 | ChatGPT Plus(有料) | GPT-4oを選択する必要あり |
| ChatGPT モバイルアプリ(iOS/Android) | ChatGPT Plus(有料) | 画像生成は同様に対応 |
| API経由の利用 | 要確認(制限あり) | 一部制限または未提供の可能性 |
なお、2025年初頭時点では人気が高いため、一部制限(回数制限や生成待ち時間)が設けられる場合があります。
利用には以下の条件を満たす必要があります。
- ChatGPT Plusプランへの加入
- GPT-4oモデルの選択
- 「画像を生成して」と入力し、応答として画像生成結果が返されること
以上の条件をクリアしていれば、あなたもすぐに4o Image Generationを使い始めることができます。
このように、GPT-4oとその画像生成機能は、「知識豊富なAI」が「高性能なビジュアル」を生み出す次世代ツールです。特別なソフトウェア不要でChatGPT内から利用できる点も大きな魅力となっています。
次章では、どこがどう進化したのかをさらに深掘りしていきます。
どこが進化したのか?
画像のクオリティ向上
ChatGPT-4oの画像生成機能は、従来のAI画像生成モデルと比較して画質が向上しています。
ぼやけや違和感のある部分が減り、より自然で高品質な画像を生成できるようになりました。
例えば、人の顔では「目の位置がずれる」「手の指が不自然になる」といった問題が従来モデルでは頻繁に発生していましたが、GPT-4oではこれらのミスが大幅に減少しています。
また、色彩や陰影の表現もリアルになり、美しい画像が出力されます。
以下は従来モデルとの比較です。
| 項目 | GPT-3.5など従来モデル | GPT-4o(最新) |
|---|---|---|
| 解像度 | 低め(荒さがある) | 高解像度対応 |
| 人物の描写 | 崩れることが多い | 安定して自然 |
| 色彩・陰影 | 単調・不自然 | 多彩で滑らか |
画像内のテキスト生成
GPT-4oでは、画像内に正確な文字を描写する能力が大幅に向上しました。
たとえば、「AI」や「Welcome」といった英語や日本語の文字を崩れることなく表示できます。
従来の画像生成AIでは、文字を含む画像を生成すると形が崩れたり、意味不明な記号になることがありました。
しかし、GPT-4oはこれらの問題を克服し、以下の用途で活用できるようになりました。
- SNS用投稿画像(例:「キャンペーン開催中!」など)
- YouTubeサムネイル
- ポスターやプレゼン資料にタイトル入り画像
この機能により、テキスト入りビジュアルを簡単かつ正確に作成できる点が大きなメリットです。
構図・キャラクター・シーンの一貫性保持
複数回画像生成を行う際、「同じキャラクターを異なる場面で登場させたい」というニーズがあります。
GPT-4oでは、一貫性を保ったキャラクターや構図の生成が可能です。
具体的には以下のようなことができます。
- 同じ人物を「立っている姿」「座っている姿」として描く
- 特定の服装や髪型を維持したままポーズだけ変更する
- 背景に登場する小物や動物を再利用する
これにより、「連続したストーリーを表現する漫画風イラスト」や「ブランドイメージを統一した広告画像」の作成に役立ちます。
一貫性を保つことでビジュアル全体のクオリティが向上します。
提示画像の理解と活用
GPT-4oはアップロードされた画像をもとに新しい画像を生成する機能も備えています。
この機能により、以下のような使い方が可能です。
- 「この写真を参考にアニメ風に描いて」とリクエスト
- 「この背景を使って別の人物を追加して」と依頼
- 「このイメージを基に構図だけ真似して」と指定
これらは「インコンテキスト学習(In-Context Learning)」によるものであり、GPT-4oならではの強みです。
テキストだけでなく画像でも指示できるため、クリエイティブな作業で非常に便利です。
背景知識を活かした生成
GPT-4oは広範な知識ベースを活用し、指示内容に応じた背景知識を反映した画像生成が可能です。
- 「ナポレオン風の男性」→それっぽい服装や髪型
- 「江戸時代の町並み」→和風建築や服装
- 「Apple製品風デザイン」→シンプルで洗練された見た目
このように単なるテキスト指示だけでなく、その意味や文脈まで深く理解して画像化する能力があります。
これにより、ユーザーは抽象的なアイデアも具体的なビジュアルとして実現できます。
多様なスタイルと柔軟な表現力
GPT-4oは多様なスタイルで柔軟な表現が可能です。
以下は代表的なスタイル例です。
- リアル風
- アニメ風
- 絵本風
- 白黒・モノクロ
- レトロ風
- SF風
- 柔らかい光、暗い影、幻想的
さらに複数スタイルを組み合わせることも可能です。
- 「かわいいアニメ風で幻想的な夜の森」
- 「シンプルでミニマルなデザイン。白背景で商品だけ中央配置」
この柔軟性によってユーザーは自身のアイデアをそのまま絵として再現できます。
以上のように、GPT-4oの画像生成はただの「AI画像作成ツール」ではなく、「高性能で人間らしい判断ができる画像クリエイター」に近づいています。
次章では、その技術の裏にある仕組みを詳しく見ていきましょう。
GPT-4oによる画像生成の仕組み
自己回帰型と拡散モデルの違い
画像生成AIには、大きく分けて「自己回帰型」と「拡散モデル」の2つの方法があります。
GPT-4oでは、これらの特徴を活用し、高品質な画像生成を実現しています。
まず、自己回帰型とは「一つ一つの要素を順番に予測して生成する方法」です。
たとえば、絵を描く際に顔の輪郭→目→鼻→口…といった具合に、要素を順番に作り上げるイメージです。
一方、拡散モデルは「最初はノイズだらけの画像から、段階的にきれいな画像を復元する方法」です。
これはMidjourneyやStable Diffusionなどで採用されており、現在の主流技術です。
| 項目 | 自己回帰型 | 拡散モデル |
|---|---|---|
| 処理方法 | 順番に少しずつ生成 | ノイズから段階的に画像を復元 |
| 得意な表現 | 一貫性、整合性 | 芸術性、高解像度の表現 |
| 弱点 | 時間がかかる、細部が粗くなる | 調整が難しい、文字生成が苦手 |
GPT-4oはこれらの技術を組み合わせることで、「整った構成」と「美しい見た目」を両立した画像生成を可能にしています。
その結果、細部まで自然で高画質な画像が出力されます。
Any-to-Anyの意味と応用
GPT-4oは「Any-to-Any」という柔軟な設計思想を持っています。
これは、「どんな入力形式からでも、どんな出力形式にも変換できる」という特徴を指します。
以下のような変換が可能です。
- テキスト → 画像(画像生成)
- 画像 → テキスト(画像の説明)
- 音声 → テキスト(音声認識)
- テキスト → 音声(読み上げ)
この柔軟性により、GPT-4oは単なる画像生成だけでなく、「画像理解」「音声指示」「会話対応」など幅広いタスクをこなすことができます。
特に画像生成では以下のような応用が可能です。
- テキストで指示 → 画像生成
- 画像をアップロード → その画像の説明や修正提案
- 会話の中で段階的に画像を調整
この柔軟な設計思想によって、ユーザーはどんな形式で情報を伝えても自然にやり取りできる点が大きな進化ポイントです。
統合モデルとしてのGPT-4oの技術的背景
これまでのAIモデルでは、テキスト用、画像用、音声用など、用途ごとに別々のモデルが必要でした。
しかしGPT-4oでは、それらを統合したマルチモーダルモデルとして設計されています。
- 異なるメディア間の連携がスムーズになる
- 画像生成と会話が自然に融合する
- 一つのモデルに学習させるだけで済むため精度が安定する
GPT-4oでは、「Transformerアーキテクチャ」に改良を加え、テキスト・画像・音声といった異なる情報を同時に処理できるようになっています。
また、「CLIP(Contrastive Language–Image Pretraining)」技術を応用しており、テキストと画像の意味的な一致を実現しています。
これにより、「赤い帽子をかぶった女の子」といった具体的な指示も自然な形で再現されます。
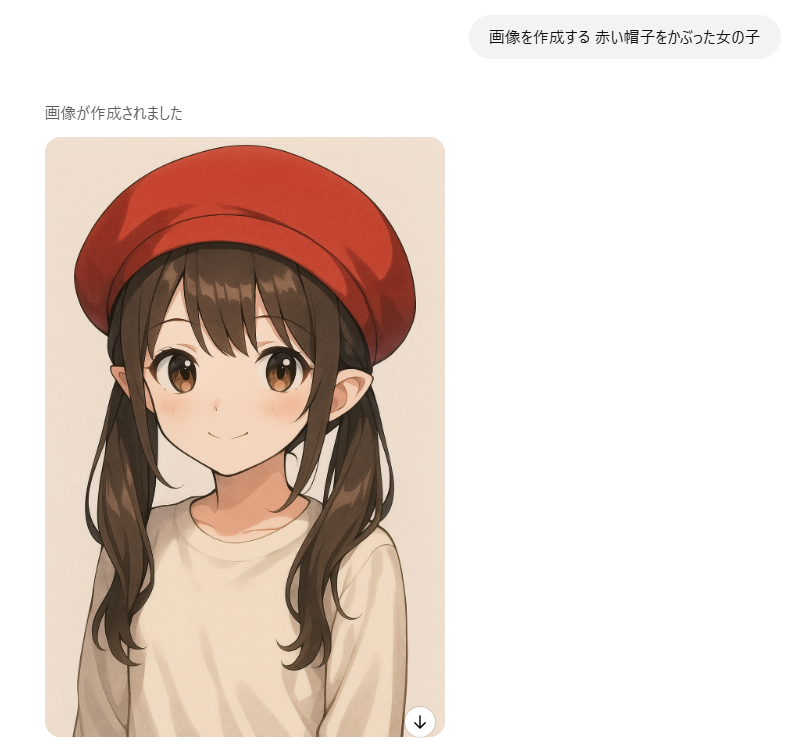
マルチターンでの会話生成
従来の画像生成AIでは、「1回の指示で完成した画像を出す」という形式が一般的でした。
しかし、GPT-4oでは「マルチターン(複数回のやり取り)」に対応しており、会話の中で画像をどんどん改善していくことができます。
たとえば、こんなやり取りが可能です。
- 「女の子が犬を抱いてる画像を作って」
- 「その犬を白いプードルにして」
- 「背景を公園に変えて」
- 「夕焼けにして、文字で“ありがとう”って入れて」
のように、チャット形式で少しずつリクエストを加えることで、理想の画像に近づけていけるのが大きな特徴です。
しかも、前の指示をしっかり記憶しており、「前と同じキャラで」や「さっきの画像の別アングルで」なども通じます。
これはまさに「対話型の画像クリエイター」と言っても過言ではありません。
以下の様なやり取りができます。
細かく指示していないので、すこし女の子の雰囲気が違いますが、会話の通りにイラストを生成してくれていますね。
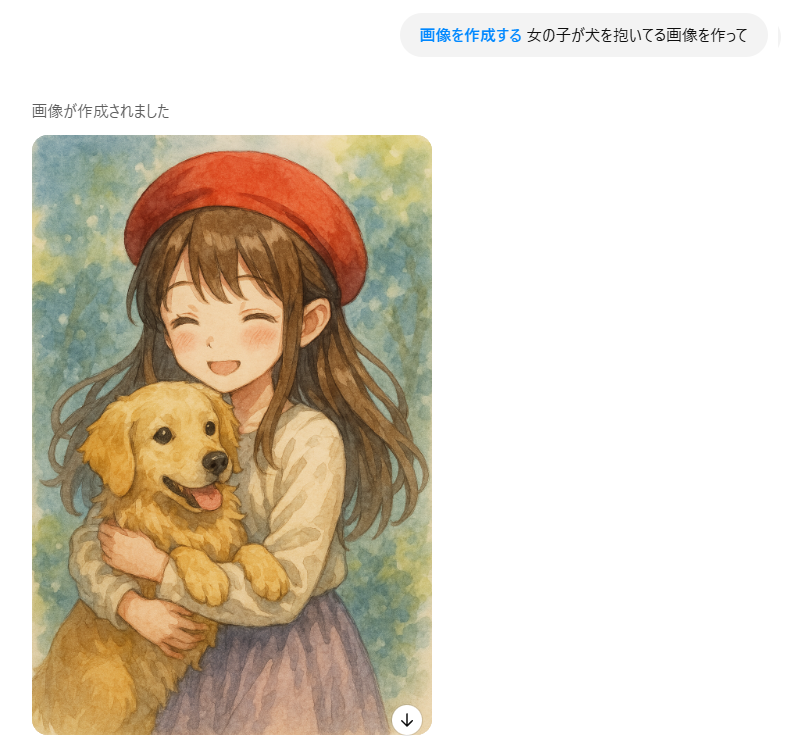

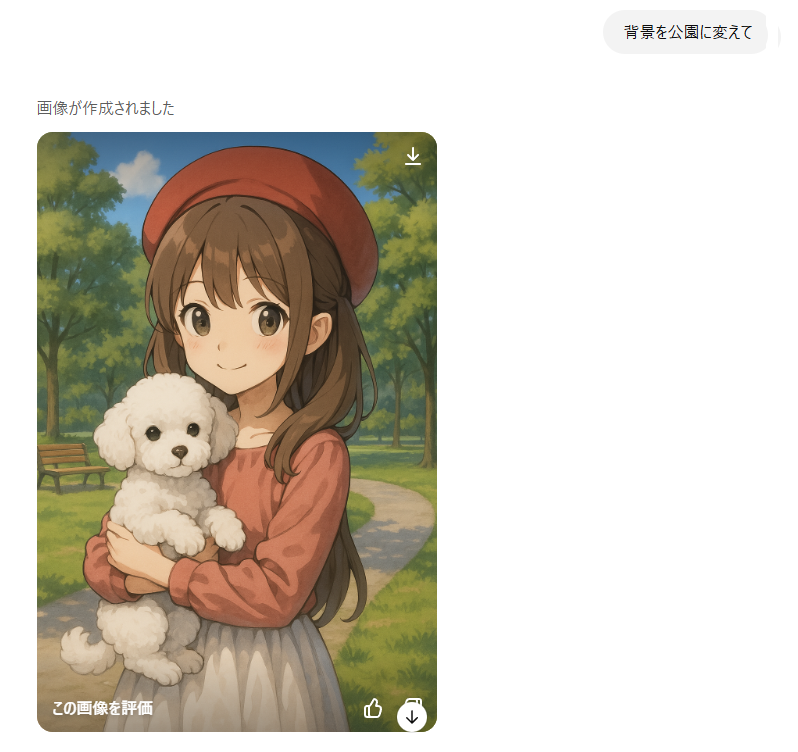

このマルチターン対応のおかげで、初心者でも安心して試行錯誤ができるようになっており、イメージがまだ固まっていない段階でも「とりあえず作ってみて、あとから調整する」という使い方が可能です。
GPT-4oの画像生成が「すごい」と言われる理由には、こうした高度な仕組みが背景にあります。
単に「きれいな画像を作るAI」ではなく、「言葉・画像・会話をすべて理解し、統合的に応えてくれるAI」として、これからの活用がますます広がっていくでしょう。
GPT-4o Image Generationのメリットとデメリット
メリット
GPT-4oの画像生成には、これまでのAIツールでは実現できなかった「高い精度」や「細かい対応力」など、たくさんのメリットがあります。
とくに初心者でも直感的に扱える点が大きく、プロのデザイナーでなくても高品質なビジュアルを作ることができます。
以下に、代表的な3つのメリットをわかりやすくご紹介します。
精度の高い画像生成
まず一番注目すべきメリットは、とにかく画像がキレイで自然という点です。
従来のAI画像生成ツールでは、手や顔がゆがんだり、背景がぼやけたりといったミスが多く見られました。
しかし、GPT-4oはその弱点を大きく克服しており、人物や物体の細部までリアルに再現できます。
- 顔のパーツの位置が正確
- 指の数や形が自然
- 背景とキャラのなじみが良い
など、今まで気になっていた部分がしっかり改善されています。
また、解像度自体も高いため、SNSや資料にそのまま使っても違和感がありません。
プロが作ったような仕上がりに近づけるのは、GPT-4oならではの強みです。
細かな指示の理解
2つ目のメリットは、とても細かいリクエストにも対応できる理解力です。
たとえば以下のような細かい指示も、GPT-4oはしっかりくみ取ってくれます。
- 「夕暮れの海辺に立つ男の子。手に風船を持っている」
- 「笑顔だけど、目はちょっと寂しそうに」
- 「背景はレトロ風の喫茶店。木のカウンターが見えるように」
こうしたニュアンスを含む指示は、文章だけでは伝わりにくいことも多いのですが、GPT-4oは言葉の裏にある「イメージ」まで読み取ってくれる力があります。
そのため、創作活動やストーリーテリング、広告制作など、感情や世界観を大事にしたい場面でも活躍します。
それぞれ生成した画像です。



テキストと画像の融合表現
3つ目の大きなメリットは、画像の中に自然な文字(テキスト)を入れることができる点です。
これまでのAI画像生成では、文字を描こうとすると…
- 文字がつぶれる
- 変な記号になる
- 英単語のつづりが間違っている
といったトラブルがよくありました。
しかし、GPT-4oではその精度が飛躍的に向上し、日本語でも英語でも、指定した通りの文字を正確に描写できるようになっています。
これによって、
- プレゼン資料のタイトル入り画像
- YouTubeサムネイル
- 商品名付きの販促画像
といった実用的なコンテンツ制作が一気にスムーズになるのです。
デメリットと対処法
もちろん、どんなに優れたAIでも「完璧」ではありません。
GPT-4oにもいくつかのデメリットや注意点があり、それらを理解して使うことが大切です。
代表的な3つの課題と、どう対応すればいいのかを紹介します。
生成速度の課題
GPT-4oは高性能なぶん、画像の生成に少し時間がかかることがあります。
とくにプロンプト(指示文)が複雑だったり、アクセスが集中している時間帯では、画像の完成までに1分以上かかる場合もあります。
対処法としては以下のような工夫が効果的です。
- 生成前にできるだけプロンプトを整理する(無駄な表現を減らす)
- 混雑しにくい時間帯(深夜や早朝)に利用する
- 必要に応じて簡易な画像から試作→詳細化する方法を使う
こうすることで、ストレスを最小限に抑えつつ、効率よく理想の画像を作ることができます。
利用制限(一時停止など)
GPT-4oの画像生成は非常に人気が高いため、一時的に利用が制限されることもあります。
これはOpenAI側がサーバーの負荷を抑えるために設けている措置で、状況によっては以下のようなメッセージが表示されることがあります。
- 「現在、画像生成機能は一時的に制限中です」
- 「GPU負荷により応答が遅れています」
このようなときは、少し時間を空けて再試行するか、日を改めてアクセスするのがベストです。
なお、有料プラン(ChatGPT Plus)でもこうした制限は一時的に発生する可能性があるため、「絶対にこの時間に生成したい」という場面では余裕をもって取り組むことが重要です。
商用利用における制約
最後の注意点は、商用利用に関する制限です。
GPT-4oの画像生成は基本的に商用利用も可能ですが、以下のような条件があります。
| 利用タイプ | 利用可否 | 補足 |
|---|---|---|
| 自分のブログやSNS | 〇 | 商用収益化している場合も基本OK |
| 広告バナーや商品画像 | △ | 著作権や肖像権に注意。違反内容はNG |
| ジブリ風アート | △ | スタイルガイドライン厳守 |
| 著名人・ブランド風画像 | × | 本人そっくりの画像やロゴ模倣などは不可 |
とくに気をつけたいのは、「実在の有名人を描くこと」や「他社のブランドロゴをまねること」です。
これらは法律的な問題につながる可能性があるため、不安な場合は生成を避けるか、専門家に確認するようにしましょう。
GPT-4o Image Generationは非常に高性能で使いやすいですが、その一方で「使い方の工夫」や「ルールの理解」が求められる場面もあります。
でも安心してください。
正しい使い方を覚えれば、初心者でも驚くほど美しくて実用的な画像が作れるようになりますよ。
次の章では、その実際の活用シーンを見ていきましょう。
実例で見る画像生成の活用シーン
マーケティング・広告資料への活用
4o Image Generationは、マーケティングや広告分野でも非常に実用的です。
なぜなら、目的に合った画像を即座に作れるからです。
たとえばキャンペーン告知や商品紹介など、ビジュアルが重要な場面でAIが強力な助っ人になります。
以下のような活用シーンが想定されます。
- セール告知バナー
- 商品の使用シーンを再現したイメージ
- イベント告知のアイキャッチ画像
特に画像内に文字を自然に描ける点は、マーケティングには欠かせません。
従来はデザイナーに依頼していた作業も、ChatGPTを使えば数分で済みます。
- 色やフォント、構図まで細かく指定できる
- ターゲット層に合った雰囲気をコントロールできる
- 他社との差別化をビジュアルで表現できる
このように、広告のスピード感とクオリティを同時に実現できます。
プレゼン・研修資料のビジュアル化
ビジネスの場では、「伝わる資料」が求められます。
文字ばかりのスライドよりも、視覚的に印象を残す画像入りの資料の方が、受け手の理解と記憶に残りやすいです。
GPT-4oの画像生成を使えば、以下のようなプレゼン資料が作成可能です。
- 経営戦略をビジュアル化した図解
- 新サービスの利用シーンを描いたイメージ図
- 研修や教育に使えるキャラクター付きのスライド
たとえば、「仕事で使うAIの未来」を説明する場合、「AIが職場で活躍する様子」をイラスト化してスライドに入れるだけで、内容が一気に伝わりやすくなります。

また、文字入り画像も作成できるので、スライドの見出しや要点を画像として表現することもできます。
(先ほどのイラストに「AI活用1」と文字を入れました)

これは視覚的に見せたい研修や教育現場でとても役立ちます。
シリーズ画像によるSNS投稿
SNSでは、見た目が9割といっても過言ではありません。
投稿に使う画像が目を引くほど、フォロワーの反応や拡散力が上がります。
GPT-4oの画像生成を使えば、「シリーズ画像」のような連続性のあるビジュアルを作ることが可能です。
たとえば…
- キャラ紹介シリーズ」:同じスタイルのキャラを毎日1人ずつ投稿
- 「名言ポスター風シリーズ」:背景と文字を変えながら連投
- 「旅ログシリーズ」:イメージ写真に地名や食べ物を合わせた画像
このように、トンマナ(統一感)を保った投稿が自動で量産できるのは、ブランドアカウントや個人インフルエンサーにとって大きな武器になります。
さらに、投稿にストーリー性を持たせることで、フォロワーの「続きを見たい!」という期待感も生み出せます。
4コマ漫画・GIF作成
クリエイターやコンテンツ発信者にとって、ストーリーのある画像を作れることは大きな魅力です。
GPT-4oは、一貫性のあるキャラや構図で複数の画像を生成できるため、4コマ漫画のような形式でも十分活用できます。
- 商品の使い方を漫画形式で伝える
- 社内のあるあるネタを4コマで表現
- 簡単なストーリーをシリーズで発信

さらに、生成した4枚の画像をつなげてGIFにすれば、簡単なアニメーションにも応用できます。
以下のような用途で活用が進んでいます。
| 用途 | 内容の一例 |
|---|---|
| エンタメ投稿 | 日常あるある、ゆるキャラの日常など |
| 広報コンテンツ | 商品PRをキャラが紹介するストーリー漫画 |
| 教育コンテンツ | 子ども向けに難しい話を漫画形式で解説する |
これまで漫画やGIFはデザイナーやイラストレーターが必要でしたが、GPT-4oなら非デザイナーでも挑戦可能です。
ビジネス向けの活用事例
GPT-4oの画像生成は、クリエイティブ用途だけでなく、ビジネスのさまざまな場面でも利用されています。
特に以下のようなケースで力を発揮します。
| シーン | 活用内容 |
|---|---|
| 企画書や提案書 | コンセプト画像、イメージビジュアルの挿入 |
| SNS運用 | ブランドカラーに合わせた画像制作 |
| ECサイト | 商品画像のバリエーション作成 |
| オウンドメディア運用 | 記事ごとのアイキャッチ画像や図解の作成 |
また、営業ツールとして「○○のメリットを1枚で伝える画像」や「Before/Afterの比較図」などをAIで作成すれば、説得力のある資料が短時間で完成します。
- 社内外のコミュニケーションがスムーズになる
- デザイナーに依頼するコストや時間を削減できる
- 提案内容が視覚的に伝わりやすくなる
このように、GPT-4oは単なる画像生成ツールではなく、「ビジネスの成果を加速させるパートナー」としての役割を果たしつつあります。
次のセクションでは、実際に使った人の評価や具体的な生成例を紹介していきます。
画像生成プロンプトの書き方・コツ
「画像を生成して」を含める構造意識
GPT-4oで画像を生成する際は、プロンプト(指示文)の書き方が結果の質を大きく左右します。
特に初心者の方がまず覚えておきたいのが、「画像を生成して」という明示的なフレーズを含めることです。
これは、ChatGPTが「今から画像を作るんだな」とはっきり理解するための合図になります。
「画像生成して」と指示を出さなくても、プロンプトの入力欄にある「画像を作成する」を選択しても、画像生成する指示が出せます。
プロンプトの基本構造は次のようになります。
「画像を生成して:●●なシーンで、▲▲が□□している。背景には◇◇が見えるように。」
たとえば、
- 「画像を生成して:雨の中、赤い傘をさした女の子が歩いている。後ろにぼんやりとした街の灯り」
- 「画像を生成して:海辺で寝そべる猫。青空と太陽が背景」
このように、「何をどう描くか」を具体的に伝えるのがポイントです。
以下に、良い例と悪い例を比べてみましょう。
| 指示文の例 | GPT-4oの理解度 | 仕上がり |
|---|---|---|
| 赤い傘をさした女の子 | 低い(何を求めているか不明) | 不明確な画像になる可能性あり |
| 画像を生成して:赤い傘をさした女の子が雨の中を歩く | 高い | 具体的なビジュアルを再現しやすい |
たとえば先ほどの指示の「赤い傘をさした女の子」で生成した画像がこれです。

より細かく指示を出した場合のイラストがこちら。

はじめのうちは、しっかり「画像を生成して」と書き、あとは絵本の文章のようにイメージを言葉にしてみましょう。
スタイルや雰囲気の明示
GPT-4oは非常に柔軟な画像生成が可能ですが、そのぶんスタイルを明確に伝えないと、仕上がりが予想とズレることがあります。
そのため、「リアル」「アニメ風」「水彩画調」「手描き風」など、見た目の雰囲気や表現方法をしっかり指定することが大切です。
たとえば、次のようにプロンプトにスタイルを組み込みましょう。
- 「アニメ風で、明るくかわいらしい感じ」
- 「リアルな油絵風の仕上がりで」
- 「落ち着いた色合いの水彩画調」
また、「明るい」「幻想的」「ダークな雰囲気」といった感情や空気感も併せて伝えると、よりイメージ通りの画像が出てきます。
| キーワード | 仕上がりの傾向 |
|---|---|
| ファンタジー風 | きらきらした光、非現実的な背景 |
| ミニマルデザイン風 | シンプルで情報が少ない |
| ノスタルジック | やわらかい色調、昔っぽい雰囲気 |
スタイルを指定することで、同じ内容でもまったく違った画像になるので、表現の幅がぐっと広がります。
ネガティブ指示(除外条件)の活用
GPT-4oでは、「〇〇しないでください」といったネガティブな指示(除外条件)も受け付けてくれます。
これを使うことで、「よくある失敗」を回避できたり、「あえて表現を制限したい」ときに便利です。
例を挙げると、
- 「画像を生成して:かわいい犬が花畑で寝ている。※人間は入れないで」
- 「画像を生成して:宇宙船のイラスト。※文字や数字は入れないで」
ネガティブ指示を使えば、より意図に忠実な画像が得られます。以下のような項目で活用可能です。
| 除外内容の例 | 効果 |
|---|---|
| 人間を描かない | 動物や自然を際立たせたいときに有効 |
| テキストを入れない | ビジュアル重視の作品に最適 |
| 暗い色を避ける | 明るくポップな印象を作りたいとき |
| カメラアングルを限定する | 見せたい角度を統一できる |
「してほしくないこと」もはっきり伝えることで、プロンプトの完成度は一段階アップします。
効果的な英語プロンプトのヒント
GPT-4oは日本語でも高精度に反応しますが、より細かく正確な画像を作りたいときは英語でプロンプトを書くと効果的です。
英語に慣れていない方でも、以下のような構文を覚えておけば大丈夫です。
A [subject] in/on [location] with [details], [style], [emotion or lighting]
- A black cat sitting on a window sill with flowers around, watercolor style, warm lighting
- A smiling boy under the cherry blossoms, anime style, no text
「例」のプロンプトでイラストを生成してみました。
A black cat sitting on a window sill with flowers around, watercolor style, warm lighting

A smiling boy under the cherry blossoms, anime style, no text

このように生成できました。
また、以下のようなよく使う英語キーワードを覚えておくと便利です。
| 日本語 | 英語プロンプト用語 |
|---|---|
| アニメ風 | anime style |
| 写実的 | realistic |
| 水彩画風 | watercolor style |
| 暗めの雰囲気 | dark tone |
| 明るい雰囲気 | bright lighting |
| 曇り空 | cloudy sky |
| 背景に花 | with flowers in background |
英語の方が表現のニュアンスをうまく伝えられる場面も多いので、慣れてきたら英語も併用して試すことをおすすめします。

画像を添えて指示する方法
ChatGPTのGPT-4oでは、ユーザーがアップロードした画像をプロンプトの一部として使うことが可能です。
たとえば、
- 「この画像を参考にして、キャラをアニメ風にして」
- 「この写真の構図をそのままにして、別のシチュエーションにして」
- 「この背景を活かして、人物を追加してください」
といった具合に、言葉で説明しづらい細かい部分を、画像で伝えることができます。
画像を活用することで、以下のような効果があります。
| 活用パターン | 効果・メリット |
|---|---|
| 構図の参考 | カメラアングルや配置を忠実に再現できる |
| 色合いの参考 | 好みの配色を画像から読み取って反映できる |
| キャラの雰囲気共有 | キャラの表情や服装などを自然に引き継げる |
| 類似画像の生成 | ベース画像をもとに新しいパターンを作れる |
この「画像+テキスト」での指示は、プロのデザイナーが使う「ラフスケッチ+指示書」に似ており、初心者でも本格的な制作指示が可能になる手段です。
このように、プロンプトの書き方次第でGPT-4oの画像生成は大きく変わります。
商用利用や禁止事項などの注意点
商用利用が可能な条件
ChatGPT-4oの画像生成機能は、商用利用も基本的に可能です。
つまり、自分のビジネスや副業、コンテンツ制作などに生成画像を活用してもOKということです。
たとえば以下のような用途で使えます。
- ブログやYouTubeのサムネイル
- SNSのプロモーション用画像
- プレゼン資料、広告バナー
- 自作グッズ、電子書籍の表紙 など
ただし、何でも自由に使えるわけではありません。
OpenAIの利用規約では、以下のような「商用利用可能な条件」が定められています。
| 条件内容 | 説明 |
|---|---|
| 利用者が正規の手段で画像を生成している | ChatGPT PlusプランやAPIを適切に利用していること |
| 利用規約やガイドラインに違反していない | 暴力表現・差別表現・誤解を招く内容などが含まれていないこと |
| 生成物に違法性や権利侵害がない | 著名人や企業ロゴなど第三者の権利を侵害しないこと |
これらを守れば、生成された画像を安心してビジネス利用できます。
ただし、商用利用時には以下の注意点も理解しておく必要があります。
生成禁止とされるケース
OpenAIは、以下のようなテーマや内容について画像生成を禁止しています。
これらに違反するとアカウント制限やBAN(利用停止)につながる可能性があります。
| 禁止ジャンル | 理由 |
|---|---|
| 暴力・グロテスク・残酷描写 | モラルおよび社会的規範に反するため |
| 性的・アダルトコンテンツ | 青少年保護および倫理的観点から |
| 差別的・ヘイト表現 | 社会的偏見や差別を助長する可能性があるため |
| 宗教・政治的な極端なプロパガンダ | 誤情報拡散や社会的対立を引き起こす恐れ |
| 実在するブランドロゴや商標模倣 | 商標権侵害および法的問題につながる可能性 |
| 偽物の著名人や公共人物の画像 | 肖像権侵害および虚偽情報拡散のリスク |
たとえば、「有名俳優の顔を使った商品PR画像」や「ディズニー風キャラクター」の生成は著作権侵害や肖像権侵害につながる可能性があるため絶対NGです。
OpenAIはこれらのポリシー違反となるプロンプトを検知し、自動で拒否する仕組みを導入しています。
こんな風に言われます。

意図せずポリシー違反にならないよう、生成前に「これは大丈夫かな?」とチェックする癖をつけましょう。
著作権・肖像権に関する注意
AIで生成した画像には、「著作権は誰に帰属するか?」という疑問があります。
OpenAIの公式見解によれば、ChatGPTで自分が生成した画像はユーザー自身が所有し、商用利用も可能です。
ただし以下の点に注意してください
1. 自分が作った画像=自由に使える
自分でプロンプトを書いて生成した画像は原則として「あなたの成果物」とみなされます。そのため以下の用途で自由に使用できます
- ブログやSNS投稿
- 自作グッズ販売
- 電子書籍表紙への使用
他人の著作物や実在人物は要注意
以下の場合には第三者の権利侵害となる可能性があります。
- 実在キャラクター模倣(例:ポケモン風デザイン)
- 有名人そっくり再現(例:トム・クルーズ風男性)
- ブランドロゴ模倣(例:NIKE風靴)
これらは法的問題につながる恐れがあるため避けるべきです。
【著作権・肖像権の注意ポイント】
| 項目 | OK/NG | 理由 |
|---|---|---|
| オリジナルのキャラや風景 | OK | 自分の創作とみなされる |
| 有名人そっくりの人物 | NG | 肖像権の侵害になる可能性あり |
| 実在ロゴに似たマーク | NG | 商標権・意匠権の侵害にあたる恐れ |
| 歴史上の人物(例:織田信長) | 条件付きOK | 公人の範囲であり、表現により問題あり得る |
万一、生成した画像でクレームを受けたり法的なトラブルになると、損害賠償などのリスクも考えられます。
不安な場合はリスク回避策を活用
もし不安がある場合は、以下のような方法でリスクを回避できます。
- AI画像は背景や補助要素にとどめ、主要部分は商用フリー素材を使う
- 画像の生成後に「これは利用して大丈夫か?」をAIに再確認する
- トレースではなく、参考程度の構図にとどめる
また、ブログや販売用コンテンツに使う場合は、「この画像はAIで生成したものです」と注釈を入れることで、誤解やトラブルの予防にもつながります。
このように、GPT-4oの画像生成は便利で強力なツールですが、「使い方」と「ルール」を正しく理解することが重要です。
次のセクションでは、実際に画像生成を始めるためのステップをわかりやすく紹介していきます。
画像生成の手順と始め方
ステップ①:ChatGPTにアクセス
ChatGPTで画像を生成するには、まずChatGPTにアクセスすることです。
2025年現在、画像生成機能(4o Image Generation)は「ChatGPT(GPT-4oモデル)」で利用できます。
- ブラウザでChatGPT公式サイト
(https://chat.openai.com)にアクセス - OpenAIアカウントでログイン(無料アカウントでもOK)
- GPT-4oモデルに切り替える(Plusユーザーなら選択可能)
無料ユーザーの場合は画像生成が制限される場合があるため、Plusプラン(月額20ドル)への加入がおすすめです。
また、モバイルアプリ(iOS/Android)でも同様に利用可能です。
スマホからでも簡単に画像生成ができるので、外出先でも手軽に利用できます。
- GPT-4oが選択できない場合は、機能がまだロールアウトされていない可能性があります。
- 画像生成は、アクセスが集中する時間帯に制限される場合があります。
ステップ②:プロンプト入力で画像生成
次に、画像を作るための指示文(プロンプト)を入力します。
これはAIに「どんな画像を作ってほしいか」を伝えるためです。
先ほどの章でも解説した通り、下のようにプロンプトを入力します。
- 「画像を生成して:青空の下、麦わら帽子をかぶった女の子が微笑んでいる。背景は田んぼ」
- 「画像を生成して:未来的な都市の夜景。上空にホバーバイクが飛んでいる」
プロンプトは日本語でも英語でも使用できます。GPT-4oは多言語に対応していますが、より詳細なニュアンスを伝えたい場合は、具体的な表現を用いることをお勧めします。
【プロンプト作成のコツ】
| ポイント | 内容例 |
|---|---|
| 登場人物 | 少女、老人、ロボットなど |
| 場所・背景 | 森の中、海辺、教室など |
| 雰囲気 | 明るい、幻想的、レトロ風 |
| スタイル | アニメ調、水彩画風など |
| 動作・表情 | 走っている、笑っているなど |
また、1回のプロンプトで気に入った画像が出ない場合もあります。
その場合は、「もう一度」「少し違う構図で」などの追加指示を出せば、再生成が可能です。
ステップ③:マルチターンで画像を調整
GPT-4oの強みは、一度の指示で終わらない「マルチターン」での画像生成です。
AIとの会話を通じて、細かい部分を修正しながら理想の画像に近づけていくことができます。
- ユーザー:「もう少し明るい色合いにして」
- GPT:「了解しました。明るく調整した画像を生成します。」
- ユーザー:「人物の表情を笑顔に変えてください」
- GPT:「笑顔に変更した画像を生成します。」
このように、AIとの対話を重ねることで、イメージに合った1枚に仕上げることができます。
マルチターンでできること
- 色合いの変更(暗く→明るく)
- 登場人物の表情・服装の変更
- 背景の差し替え
- 画面構図の調整(もっとズームイン、引きで見せてなど)
- 画像の再構成(例:キャラはそのままで場所だけ変える)
プロンプト1発勝負ではなく、「画像づくりをAIと一緒に進める」という感覚で使えるのが、ChatGPTの4o Image Generationの面白いところです。
ユーザーアップロード画像の活用
前の章でも解説した通り、ChatGPTでは、自分の持っている画像をアップロードして、それを基に新しい画像を生成することもできます。
画像アップロードは、画面左下の「+」マークから簡単に行えます。
画像をアップロードした後、以下の手順で指示を出すことで、よりイメージに近い画像を得られます。
- 画像をアップロード
- どの要素を使ってほしいかを明記
- どんなスタイルや変更を加えたいかを具体的に記述
といったステップで伝えると、より思い通りの仕上がりになります。
APIによる生成・料金・制限
ChatGPTの画像生成機能は、APIを使って外部アプリや自社サービスと連携させることもできます。これは開発者向けの機能ですが、業務で自動化したい場合に便利です。
- ユーザーが入力した内容から画像を自動生成してサイトに表示
- 定期的に画像を更新するシステムを構築
- 画像付きレポートや資料を自動作成
API利用には、OpenAIの開発者アカウントが必要です。
【料金プラン概要(2025年3月時点)】
| プラン | 内容 |
|---|---|
| 無料プラン | 回数制限あり(画像生成はタイミングにより不可) |
| ChatGPT Plus($20) | GPT-4o利用可。画像生成も安定して使える |
| API利用 | 画像1枚ごとに課金(料金は利用状況によって変動) |
※料金体系やAPI仕様は変更されることがあるため、OpenAI公式ドキュメント(https://platform.openai.com/docs/overview)で最新情報を確認してください。
無料プランでは、アクセスが集中している時間帯に画像生成ができない場合があります。
継続的に利用したい場合は、ChatGPT Plusプランへの加入がおすすめです。
以上が、ChatGPTで画像を生成するための手順と始め方の解説でした。
次のセクションでは、他の画像生成AIとの違いを比べながら、GPT-4oの強みをさらに深掘りしていきます。
GPT-4oと他モデルの違い
GPT-4o vs Midjourney
GPT-4oとMidjourneyは、それぞれ異なる強みを持つ画像生成AIです。
以下に主な違いをまとめます。
| 比較項目 | GPT-4o(ChatGPT) | Midjourney |
|---|---|---|
| 利用方法 | ChatGPT内で会話形式 | Discord内のBotチャット形式 |
| 指示のやり方 | テキスト会話形式、マルチターン対応 | コマンド形式(例:/imagine) |
| プロンプト自由度 | 高い(多言語対応) | 高い(芸術的な描画力) |
| 画像スタイル | 多様(リアル、アニメなど) | アート寄り・幻想的な仕上がり |
| テキスト生成 | 高精度(文字入り画像対応) | 苦手(文字が崩れることあり) |
| 調整のしやすさ | 会話で繰り返し調整可能 | バリエーション・アップスケール |
| 日本語対応 | 完全対応 | 英語推奨 |
Midjourneyは芸術的な画像生成を得意としており、「映える」ビジュアル制作に適しています。
一方、GPT-4oは日本語対応や文字入り画像生成など、実用性と柔軟性に優れています。
- 日本語でそのまま指示したい
- 会話しながら「もうちょっと明るく」「表情を変えて」と微調整したい
- 文字入りのバナー画像やサムネを作りたい
このように、「アート表現のMidjourney」「実用性・柔軟性のGPT-4o」という使い分けが最適です。
GPT-4o vs Stable Diffusion
Stable Diffusionは、オープンソースで公開されている画像生成AIで、自分のPCにインストールしてカスタマイズできる自由度の高さが特長です。
GPT-4oとは開発思想も使用感も異なります。
【主な違いまとめ】
| 比較項目 | GPT-4o(ChatGPT) | Stable Diffusion |
|---|---|---|
| 利用環境 | クラウド型(ブラウザでOK) | ローカル(PCにセットアップが必要) |
| 操作のしやすさ | 会話形式で直感的に操作可能 | 設定が多く、知識が必要 |
| カスタマイズ性 | 低い(既存のAIをそのまま使用) | 高い(LoRAやモデル変更で個別調整可能) |
| 処理速度 | やや遅め(クラウドの混雑に左右される) | ローカル環境によって異なる |
| モデル追加 | 不可 | 自作モデルや学習モデルの追加が可能 |
| 商用利用の自由度 | 高いが制限あり | 高い(自己責任で自由に使える) |
Stable Diffusionは、使いこなせばアニメ調や美少女系、独自世界観のイラストを作るのに適しています。
ただし、「パソコンへの環境構築が必要で、やや中〜上級者向け」です。
- 初心者や非エンジニアの方
- 手軽にクオリティの高い画像をすぐ作りたい人
- テキストと画像を同時に扱いたい人
GPT-4oはクラウド上ですぐ使えて、会話だけで完結するのが魅力なので、上記のような方は、GPT-4oの方が圧倒的に向いています。
GPT-4oの強みと弱み
最後に、GPT-4oの画像生成機能における「強み」と「弱み」を整理しておきましょう。
- 日本語対応で自然なやりとり
- マルチターンで細かい調整可能
- テキスト入り画像生成に強い
- スタイル幅広く汎用性高い
- 芸術的表現ではMidjourneyに劣る
- 背景や手指描写が甘くなる場合あり
- 混雑時処理速度低下
- 商用利用時ポリシー確認必須
総合的に見てGPT-4oは、「創作よりも実用を重視したい」「日本語で完結したい」「一緒にアイデアを出し合いながら作りたい」という人にとって、非常にバランスの取れた画像生成ツールです。
また、MidjourneyやStable Diffusionと組み合わせて、「初稿はGPT-4oで、仕上げは他AIで」といった使い分けも今後注目されそうです。
次のセクションでは、これらの技術の進化がもたらす未来や、AI画像生成の可能性について見ていきます。
今後の可能性
ビジネス利用の本格化
GPT-4oの画像生成機能は、今後ますますビジネスの現場で活用が進んでいくと期待されています。
なぜなら、手軽に高品質なビジュアルを作れるツールは、コストと時間を大幅に削減できるからです。
例えば、これまでならデザイナーに外注していた広告バナーやSNS用画像も、GPT-4oを使えば数分で自作できます。これにより、
- 少人数のスタートアップ
- 個人の副業・スモールビジネス
- ブログ・YouTubeなどのクリエイター
といった層が、外注せずに自分で魅力的な画像を制作できる時代が到来するでしょう。
【GPT-4oがもたらすビジネスの変化】
| 活用シーン | これまで | GPT-4o活用後の変化 |
|---|---|---|
| SNSマーケティング画像 | デザイナー依頼+数日~数万円 | 数分で自作。費用ほぼゼロ |
| プレゼン資料の表紙や図解 | PowerPointや画像素材を手作業編集 | テキスト入力だけで自動生成 |
| サムネイル制作 | Photoshopなどの専門知識が必要 | 会話だけでプロ並みの仕上がりに |
| 広告バナー、LP用イラスト | 外注が必要で納期も長い | その場で修正・やり直しが何度でも可能 |
特に、文字入り画像の精度が高いという特長は、「ただの画像生成AI」ではなく「実用ツール」としての価値を一気に高めています。
そして、マルチターンでのやりとりにより、納得がいくまで微調整できるのも大きなポイント。デザイン経験のない人でも、納得のいく画像を自分の手で作れる時代が来ました。
画像生成AIの進化と未来展望
GPT-4oだけでなく、AI画像生成そのものが、今まさに大きな進化の波に乗っています。
そして、今後さらに高性能かつ自然な画像生成が可能になる未来が見え始めています。
今の時点で見えている未来の可能性をいくつか挙げてみましょう。
1.映像やアニメーションへの進化
現状は静止画の生成がメインですが、今後は「動画生成」や「アニメーション作成」までAIでできるようになると予想されます。
すでに、連続した画像をつなげてGIF化するような技術は始まっています。
たとえば、
- 「このキャラクターが笑って→歩いて→振り向く」動画
- 「景色が時間と共に変化するタイムラプス映像」
なども、数分で作れるようになる日が近づいています。
2.インタラクティブな生成(音声やジェスチャー対応)
今はテキストで指示を出す形ですが、将来的には音声入力やジェスチャーでも「画像生成の指示」ができるようになるでしょう。
- この写真、背景を夜景に変えて」→音声だけで操作
- 手で形を描いて、その通りの構図でイラストを生成
といった、より直感的で誰でも使いやすい形に進化していくと考えられます。
AIがアイデアを提案するフェーズへ
今までは「人間がアイデアを考え、AIが描く」形でしたが、これからはAIがデザイン案を提案する役割も果たしてくるでしょう。
例えば、
- 「この商品のプロモーションに合うイメージを5つ出して」
- 「このブログタイトルに合うサムネイル構成を提案して」
といった具合に、人間が考える前にAIがアイデアの「たたき台」を出してくれるという新しいワークフローが生まれます。
4.プロンプトレス生成(言わなくても伝わるAI)
さらに先の未来では、指示文(プロンプト)さえいらなくなる可能性があります。
たとえば、ユーザーの過去の制作傾向や、Web上で見ていた情報をAIが学習し、
- 「あなたの今の気分に合う画像を提案します」
- 「今の流行に合わせて、インパクトあるサムネイルを自動生成しました」
といったように、“おまかせ”でセンスのいい画像が出てくる未来も想像できます。
5.法的・倫理的な整備と社会との共存
最後に、技術が進化するにつれて、「どこまでがセーフで、どこからがアウトなのか?」というルール整備も同時に進んでいく必要があります。
- 著作権や肖像権をどう扱うか
- フェイク画像のリスク管理
- 子どもや高齢者でも安心して使えるUI・UXの確保
こうした視点での法整備や倫理ガイドラインが整えば、AI画像生成は社会にとって「危険なツール」ではなく、「未来の創造力を支える味方」になっていくはずです。
このように、GPT-4oをはじめとする画像生成AIは、今後さらに進化しながら、より身近に、より創造的なパートナーになっていくことが期待されています。
次の時代は、誰でも「想像をそのままカタチにできる」世界。まさに、AIと共に描く未来が始まっています。
まとめ
今回は、「4o Image Generation(GPT-4oの画像生成)」について、基本情報から進化のポイント、実用性や他AIとの比較まで詳しく解説してきました。
今後ますます注目されるこの技術をうまく活用することで、ビジネスも創作も大きく加速します。
最後にポイントを振り返っておきましょう。
- 画像生成の精度が大幅向上
- 柔軟な会話形式で調整可能
- 実務にも応用しやすい性能
- プロンプト次第で品質が変化
- 商用利用には注意が必要
- 他AIとの違いを理解して選択
ChatGPT-4oの画像生成機能は、これからのビジュアル制作を根本から変える力を持っています。
うまく使いこなして、表現の幅を広げていきましょう。
最後までお読みいただきありがとうございました。




